SharePoint Demands Performance and Scalability
Tips and tricks to help you get the most out of your SharePoint installation.
Content provided by TechNet Magazine, Microsoft's premier publication for IT Professionals
SharePoint has become an extremely popular Microsoft product. As is well known, it's a portal platform and provides a great number of needed applications for collaboration among different company groups or even between different companies. It also includes process management, document management and other major applications, all part of SharePoint's array of features.
It allows you to develop other applications, as well, either extensions of these applications or completely new applications in the SharePoint platform. The goal is to allow you to rapidly develop a new application without having to start everything from scratch.
Its popularity has grown to the point that companies are standardizing their enterprise portal strategies on SharePoint. They use it as the basis for developing their interactive applications, especially if they have to be content- or document-rich or more collaborative. Those applications can be easily developed in SharePoint for internal or external use.
However, this rapidly growing popularity has its flip side, and it's not encouraging. As increasing numbers of people use it, major performance and scalability bottlenecks start to occur. They revolve around the fact that SharePoint makes heavy use of the SQL Server database for everything it shows. This includes pages shown to users, including structured data or documents.
This can be Word docs, PDFs, Excel, PowerPoint or any other document you're trying to share. All are coming from the database. SharePoint's heavy dependence on the database results in the database very quickly becoming the bottleneck. Thus, a growing and frequent complaint is that SharePoint's response times are becoming more unacceptable when increasing loads are placed on it. However, IT and enterprise users love the product due to its many built-in features, ease of use and ease of administration and configuration.
In this article, I'll focus on how you can eliminate or at least minimize these performance issues, but continue taking advantage of SharePoint and its many attributes.
Performance Issues
There are many things that have a negative impact on SharePoint performance. These include Indexing/Crawling, backup of SQL and tape, miscellaneous timer jobs and large list operations. There's also the issue of SQL Server not being fully optimized based on the type of usage you envision in SharePoint, and not having enough instances of SQL Server. However, these issues are already discussed in various other articles and therefore I won't focus on them. However, please note that probably the most important optimization you could make from the above list is SQL database performance tuning. This is because SharePoint makes heavy use of the database and any optimization there would give dividends.
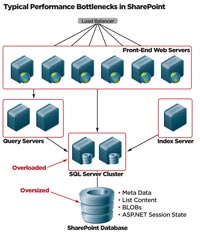
[Click on image for larger view.] |
| Figure 1. Typical SharePoint deployment with bottlenecks. |
My focus in this article is on areas that are rarely discussed and could help boost SharePoint performance and scalability. These include binary large object data (BLOB) being stored in the database, lists being fetched over and over again from the database, View State being heavy and slowing down response times, JavaScript and CSS files requiring multiple separate HTTP Get calls by the browser, and burdening the SQL database by storing ASP.NET Session State in it. If these areas are optimized, they yield a considerable performance and scalability boost to SharePoint.
Let's start with BLOB storage issue. SharePoint is a document-intensive application. This means it makes heavy use of documents going back and forth from the database. But taking these docs outside the database and storing them elsewhere, or externalizing them, allows document delivery to the user to be significantly improved. This represents one performance and scalability boost.
A second one involves structured data shown to the user as SharePoint calls lists. There are many of these lists that you, as SharePoint administrator, define as part of your portal. All these lists are fetching data from the database.
Unlike unstructured BLOBs, this is structured relational data coming from the database and is an excellent candidate for caching. It can be cached in the Web front-end tier, rather than always going back and forth from the database. But the key here is that it be cached intelligently to always keep data fresh, correct and in sync with the database. If anybody changes that data in the database, the cached copy is correct. List data is another good candidate for being cached.
ViewState poses a third issue and is an area that can be tapped to considerably improve SharePoint performance. ViewState is not a SharePoint concept, but an ASP.NET one. But because SharePoint is an ASP.NET-based product, it also experiences the same performance issues as other ASP.NET applications with regard to ViewState.
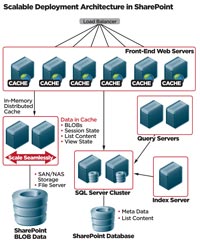
[Click on image for larger view.] |
| Figure 2. SharePoint with externalized BLOBs and distributed caching. |
Caching ViewState, however, improves response time to the user because the payload going from the Web server to the user's browser will be smaller. In this instance, ViewState is not sent with it, but instead a tag relating to ViewState is sent to the user and the actual ViewState is cached.
Different client-size JavaScript files pose a fourth area that needs optimization. This is more an ASP.NET application issue, rather than a SharePoint one. In this instance, a Web page sent to the browser usually contains many JavaScript files that have to be included to run in the browser. Additionally, each JavaScript files contains a lot of extra characters, line breaks and so on that increase its size and slow down its travel from the Web server to the user's browser.
The browser makes separate calls to load those multiple JavaScript files. For instance, in the event you have loaded a Web page, the browser reads that Web page's content and understands it has to load four or five different JavaScript files as part of the Web page.
That Web page actually makes four or five extra calls to the Web server to separately fetch those files. However, if you can combine all those files into one JavaScript file, you save the number of calls the Web browser is making to fetch them all.
You can perform this manually or program it on the fly. Any JavaScript being sent from the Web server to the browser can then be merged from multiple JavaScripts into one and only that one file is sent to the browser.
And, if you can somehow reduce the size of this merged Javascript file -- sometimes called "minifying" -- it would travel faster to the browser and improve response time for the user. However, keep in mind that if you don't do this very carefully, you can break the core SharePoint functionality.
A fifth SharePoint performance issue deals with session data storage like in any ASP.NET application. By default, out of the box, SharePoint stores all sessions in the SQL Server database. Those sessions can be removed from it and kept in a faster, more scalable storage, such as an in-memory distributed cache. The result is a considerably reduced database load.
If the above five areas are optimized by using these techniques, about 50 percent of the traffic previously going to the database no longer goes there. Now, your database can handle five times more load because you've just cut down 50 percent of the traffic.
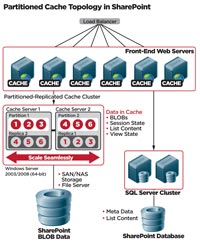
[Click on image for larger view.] |
| Figure 3. SharePoint with partitioned-replicated cache topology. |
Resolving Those Issues
With those issues as our background, how do you go about resolving them to ensure that those bottlenecks are eliminated? The first step is to remove the BLOBs from the SQL Server database and store them outside in the file system. This is called externalizing the BLOBs. You'll be surprised at how much of the database data is being consumed by these BLOBs.
The reason for externalizing BLOBs is because traditional relational databases are not designed to store large binary data or BLOBs. They were designed to store structured data, which can be indexed so you can run queries on it.
Microsoft chose to store the BLOBs in the SQL Server database and that has a performance impact. It's not the fastest way to read the BLOBs every time from the database. But performance can be vastly improved when those BLOBs are moved to an external file storage system that's optimized for storing and reading files at a time.
However, for performance sake, it's not enough to just externalize BLOBs. The SharePoint user still has to go to a common file system disk to read every BLOB every time he wants it. And, in order to read a BLOB, SharePoint still has to obtain its metadata from the database. Therefore, it's not the fastest way to deal with BLOBs. However, it's a lot faster if all the BLOBs are kept in the file system storage, but frequently used BLOBs are cached in memory close to SharePoint's front-end servers. Every time the user wants to read those BLOBs it's extremely fast because it's right there in memory available to the user. SharePoint provides disk-based BLOB caching that's very useful but is a standalone cache for each Web front-end server instead of a common shared cache for the entire Web farm.
A combination of externalizing and caching is required to optimize performance. This is the most important area of SharePoint to optimize because BLOBs are the heaviest pieces of data a user will read.
A good guess is you'll take out at least 90 percent of your data from the database, depending on the application. Suddenly, your database will feel extremely light. Previously, you might have had hundreds of gigabytes worth of data in the database. But now you'll have only 10 percent to 15 percent of that left because all BLOBs are removed. Again, it depends on the nature of the application. Some will have more than others. On average, however, about 80 percent to 90 percent of the data is used up as BLOBs.
Microsoft provides this capability in SharePoint, which requires some programming. You can have your developers do this programming or you can look for third-party products that help. Microsoft has an external BLOB storage interface or capability called External BLOB Storage (EBS). If you provide an EBS plug-in, then SharePoint knows it no longer should save all those documents in the database. Instead, it passes them on to the EBS module registered with SharePoint at the front-end Web server level. Your developers should understand the Microsoft EBS interface and, based on that interface, be able to develop your own externalization module. Additionally, note that in EBS, every time you update a BLOB a new document is created and stored and old ones are not removed. So you have to take care of removing unreferenced BLOBs yourself.
You can also opt for a commercial solution. Here's what you should expect from it: It should analyze the existing database, identify all the BLOBs that need to be externalized and ask to specify locations where those BLOBs should be stored. That location can be a simple disk on a file server or SAN storage seen as a folder.
Once you specify that location, the commercial solution should automatically go and move all the BLOBs out of the database into the file system storage or SAN storage. Once it's done, it automatically configures SharePoint so that it has an EBS provider. SharePoint then knows that from now on it won't try to find that BLOB in the database. Instead it will ask the EBS module to go and get it from the external store. The commercial EBS module would then know where to go and get the BLOB storage. The commercial solution should also take care of cleanup of unreferenced BLOBs.
This is how you really gain the performance and scalability in terms of the BLOB, which consume almost 90 percent of your data storage in a SQL Server database.
Regardless whether it's in-house developed or commercial, that module is installed on the Web front-end servers of the SharePoint deployment. SharePoint calls that module when a document is to be read or written. When a new document is added, it goes to the external storage. Whenever you read a document, SharePoint will query the module to give you that document. The same procedure is applied to update or remove documents.
Without this initial step, you can't get a noticeable performance boost. This first gain in performance is due to storing BLOBs in the file system, thus eliminating the need to continually go to the SQL Server database, which doesn't specialize in storing BLOB data. Rather, it specializes in storing structured relational data.
Caching BLOBs is a second, even bigger performance boost, which doesn't occur unless you perform external BLOB storage. There are several caching methods. BLOBs can be stored on a disk in a common file system folder. Or you can use a SAN device or NAS appliance, allowing you to store a lot of data where you also have redundancy built in. But your Web front-end will remain a different box. Using a hard disk to go and read BLOBs is faster than going to the database, but it's still not the fastest way to do this.
You have the option of using disk-based caching for BLOBs that comes with SharePoint, and I recommend that you opt for an in-memory cache of frequently used BLOBs. This is because you've already achieved a performance boost from externalizing BLOBs from database to file system, and now you're ready for the next level of performance boost from in-memory caching.
If you're going to cache BLOBs in memory, make sure you also have a distributed cache that can synchronize cache changes across multiple servers. Many of these caches provide a combination of an OutProc or remote distributed cache and a Client Cache that is InProc to your worker process on the Web front-end and can contain a smaller subset of frequently used BLOBs. This is because your SharePoint is most likely deployed in a Web farm and a standalone cache won't be appropriate. Therefore, a shared cache is more appropriate here. This cache won't contain all your BLOBs, but only the most recently used ones, because a distributed cache is normally in-memory and therefore you can't cache all the BLOBs in it.
But if you keep a moving window of the BLOBs each Web server needs, you cache it so the next time you'll find it in the cache. Your cache may be only 10 percent of actual BLOB storage. But it will still allow you to read those frequently used BLOBs over and over again. This alone reduces traffic not only to the database, but also to the BLOB storage -- and this will give you the biggest performance boost.
With BLOB caching aside, you now have to consider the second-most used data. The majority of the structured data SharePoint displayed to the user comes in the form of lists. Those could be documents, tasks, schedule entries, events and so on. Anything the SharePoint portal is showing to the user is being shown as lists. Other than BLOBs, you have to organize virtually everything you use in SharePoint in the form of lists. Hence, the user can search on the list, view a subset of it, select an item from the list, make changes to it and so on.
Distributed caching comes into play again here by caching the content of each list. Like the BLOBs, caching a list in the Web front-end reduces the number of database trips. That same data can be obtained from the cache. By caching BLOBs and lists, you've pretty much taken care of most data coming from SharePoint. Note that SharePoint provides standalone caching of list output, but in a Web farm you need a shared, common distributed cache.
So, it's ideal to cache those lists in memory in the front-end servers. However, they should be cached in such a way that any time data in those lists changes, the cache is updated. Thus, the cache is always correct and fresh. But at the same time, while data is not changing, the user can quickly go and read it from a close-by, in-memory cache.
The majority of activity users will engage in deals with lists, and they'll go through different pages. Every page will show some form of list. They'll click through a list and open some docs, which are the BLOBs. However, most of the time, they're viewing lists or making changes to those lists. This activity represents an ideal candidate for caching in the front-end servers.
Like BLOB caching, you can also choose to use the built-in, standalone caching of SharePoint for list output. Or you can acquire a commercial solution that provides a shared cache for the Web farm.
Commercial products provide you with all these capabilities. On the other hand, you should expect the selected commercial version to identify lists to be cached, the ones you don't want to cache, and clearly define the dependencies so that if a user changes the data in the database, the list automatically updates itself.
Once you specify that information, it should be propagated to the underlying cache and then made available to all front-end servers. Each front-end server would then know what to cache and what not to cache. Some commercial solutions use a distributed cache underneath, which means the cache is synchronized across multiple front-end servers. If any one server updates an item in the list, that update is immediately and automatically made available to all other servers. By using the commercial version, you're incorporating this capability more expeditiously into your SharePoint portal.
Caching ViewState also solves the issue of user response time and boosts performance. ViewState is an encrypted string of data sent back to the browser. When a user performs a post-back operation on a form, ViewState is then sent back to the browser. In the post-back, the browser sends the same ViewState back to the Web server so the Web server can go back to the older copy of the data.
However, a ViewState can become exceedingly large. It can be anywhere from 1k to 20K of data -- or even more -- depending on how large the data-entry form is. There's no need to send the entire ViewState to the browser because that's a long trip going over the Internet.
Instead, you cache ViewState and only send a unique identifier to the browser. When the next request comes, take that the unique identifier and find the ViewState corresponding to it in the cache, plug it back into the page and then give that page back to the SharePoint application. It can then use ViewState as it needs to.
When you cache ViewState, a smaller payload is sent to the browser. A small payload means better user response. Also, bandwidth consumption from the Web server to the user's browser is less. In total, it means better throughput and more scalability for the SharePoint Web farm.
Now, we go into the JavaScript files. The concept here is, a typical Web page that SharePoint delivers to the user has one or more JavaScript files included so that the client side JavaScript code can run in the browser. For each file, the browser issues a separate request to read that file from the Web server. The goal is to reduce the number of those requests coming to the server.
Ideally, you want to merge all JavaScript files on the fly into one and send a modified Web page to the browser so that instead of including five different JavaScript files, those are merged into one. From a browser's perspective, it only needs to load that one file. It makes only one trip for the JavaScript file instead of making five trips.
Instead of the browser making five extra trips to the Web server to load five separate JavaScript files, those five files are merged into one as a first step. As a second step, the Web page is modified so that it only includes one merged file rather than the five files.
In effect, the browser is being told to make one extra trip on the fly instead of five to load the larger JavaScript file. This larger file has all the JavaScript code from the files. As a result the number of hits on SharePoint's Web farm is considerably reduced.
When it comes to session state storage, one has to keep in mind that SharePoint is an ASP.NET application. This means it has ASP.NET session state, and SharePoint stores all those sessions in the database, which is not an ideal place for session storage. If both ASP.NET and SharePoint sessions are kept in an in-memory distributed cache, they'll be much faster to access from the Web front-end server than going to the database. And, depending on whether you have a 32-bit or 64-bit Web front-end server, you could choose to store ASP.NET session state on the Web front-end server or have a separate dedicated caching server that's much faster to access than SQL Server.
Microsoft's ASP.NET offers three session storage options: InProc, StateServer and SqlServer. SharePoint, by default, uses the SqlServer storage option. Microsoft has chosen to use SqlServer, which is the better of the two options. However, session data is temporary and transient in nature. Hence, there's no need to keep it in the database. When you keep it there, you have to delete it when the session expires; in fact, there's a separate agent that's run for this cleanup job in the database. Therefore, you might as well keep it in an in-memory cache, which is much faster and more scalable. A distributed cache also replicates sessions, which adds more reliability to them -- even more than a database would.
Caching Traits and Topologies
Aside from the major features described previously, there are other important traits of distributed caching that you must keep in mind for SharePoint. Those include good performance, high scalability, high reliability, high availability, expirations and evictions.
Distributed caching must demonstrate the highest performance possible and be able to scale seamlessly when your applications need to scale. Scalability refers to adding more cache severs to your environment, and as you do so, increasing your transactions-per-second capacity linearly. Plus, distributed caching must be inherently reliable so there's no data loss when a cache server goes down. Also, as a storage medium for your application, the cache must be up 100 percent of the time. When you add or remove a cache server from your cluster, it should be performed without interruptions or stoppages.
Expirations permit a cache to automatically remove a cached item after a certain time. Expirations can be either on absolute time or idle time. Absolute-time expiration removes an item at a given date-time and allows you to ensure that a cached item won't become stale because data in the database might change by this time. An idle-time expiration removes an item if nobody touches it for a given time period and allows you to automatically clean up unused items.
As for evictions, a distributed cache stores data in-memory and therefore must handle situations when the cache is full and has consumed all the memory available to it. When a cache is full, some items have to be removed to make room for new items. A cache automatically evicts items based on an eviction policy. Three common ones are Least Frequently Used, Least Recently Used and Priority. Some caches also allow you to specify that no item should be evicted and instead the cache should stop accepting new items until some items automatically expire. Eviction is different from expiration in that expiration is specified by you for each cached item differently, whereas eviction happens when the cache is fully regardless of whether items have expired or not.
Scalability in a distributed cache is achieved by selecting an intelligent way to store the data in the cache. This is usually called a caching topology. The most scalable caching topology for SharePoint would including data partitioning and data replication at the same time -- a kind of hybrid of the two. A client-side cache -- client here meaning SharePoint front-end servers -- would also add a lot of value for scalability by keeping the most-frequently used data close to the client. Let's say, you, the user have a separate caching tier because you have four or more servers in the front-end Web farm. You could use a partitioned-replicated caching topology in the caching tier and then use a client cache in the front-end servers.
Partitioned cache is a highly scalable topology for update-intensive or transactional data that needs to be cached. It's excellent for environments where you need to perform updates at least as many times as you're doing reads -- or fairly close to it, or maybe even doing more than the reads. It partitions the cache. As you add more cache servers, the cache is further partitioned in such a way that almost one Nth -- N being the number of nodes -- of the cache is stored on each cache server.
Partitioned cache with replication provides the option of backing up, or replicating, each partition onto a different cache server to maintain reliability. Client cache fits on the application server and close to the application. It's usually a small subset of the actual large distributed cache, and it's a subset based on what that application at that moment in time has been requesting. Whatever that application requests, a copy of it is kept in the client cache. The next time that application wants the same data, it'll automatically find it in the client cache. Having a client cache hands you an additional performance and scalability boost.